I had to call the Inland Revenue (HMRC) this morning. After the automated intro you connect to a speech-recognition system which asks you why you are calling:
"Tell me in a few words what you are calling about."Naturally it's both useless and annoying. It recognises speech at the level of individual keywords and can't handle any conceptual complexity. Many of the pre-programmed responses tell you to check a website or call some other number - at which point it hangs up. It's very unwilling to let you talk to a human being.
After three calls and being disconnected each time, I found the right series of lies to allow this idiot-gatekeeper to connect me to a human being. At which point I was able to transact some complications in the management of the tax on my late mother's estate.
Why is it so hard?
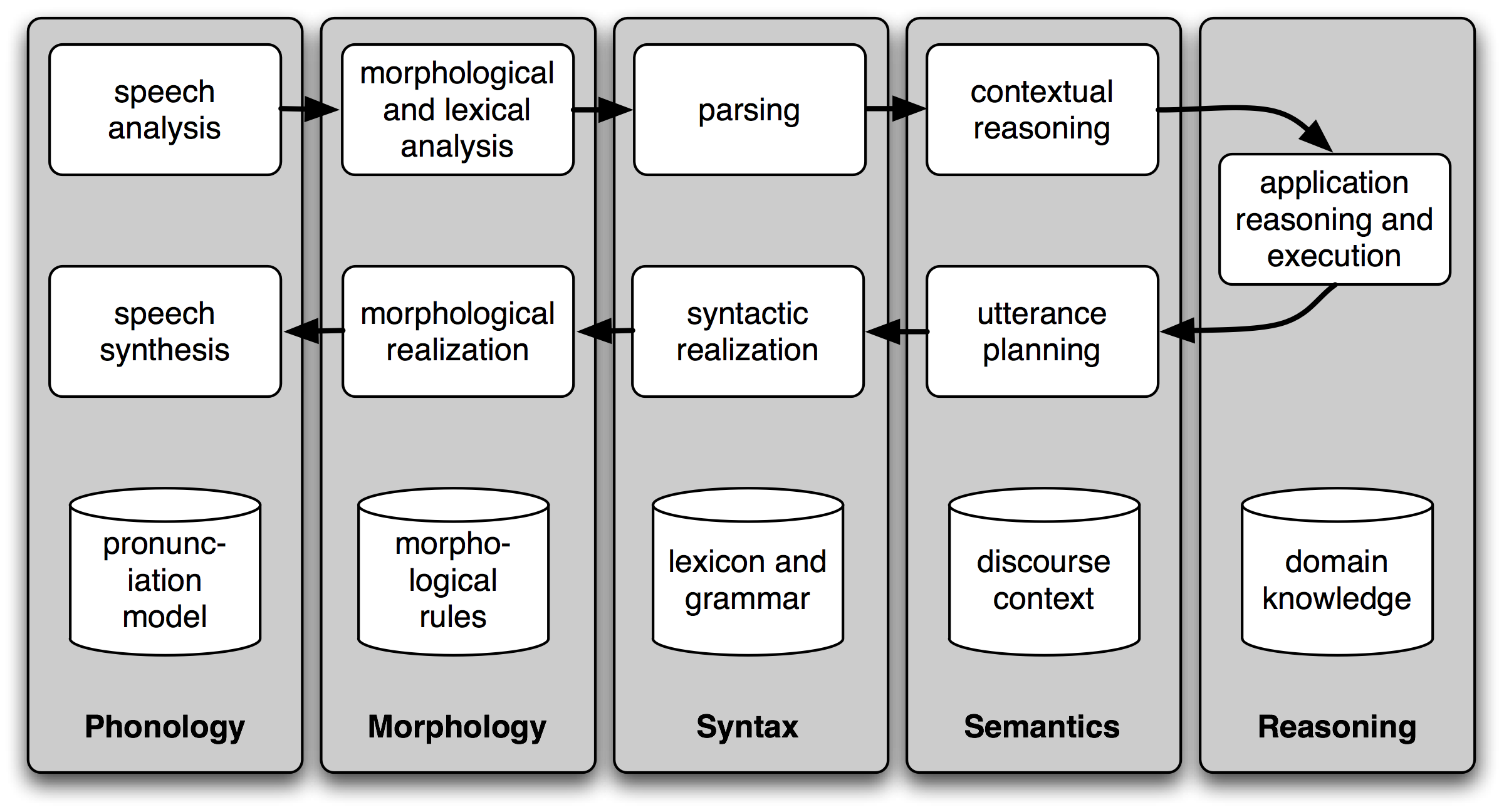
When we speak a meaningful sentence, it's not hard to create a useful knowledge representation of what was said - AI researchers have known how to parse sentences and create meaning-structures such as semantic nets for ages. 'Understanding' means doing something appropriate with the resulting semantic net - either use logical connections to derive consequences, or load associated semantic nets for things like problem reframing or context management.
Example:
"How much tax do I owe?"could be translated into this semantic net:
[Parameter(caller)] - owes - [Variable(tax-amount)]along with a processing script which says something like:
1. Identify 'caller' and add this information to the query semantic net.Developing the 'scripts', which encompass a bunch of stuff like inference, abduction, induction, conversation rules, pragmatics, ..., is harder than the knowledge representation and database loading.
2. Add in missing contextual information, eg an implicit 'for the previous tax year'.
3. Compute the variable 'tax-amount'.
4. Compute a semantic net like this:
[Parameter(caller)] - owes - [Parameter(tax)] - for - [Parameter(prev-tax-year)]
5. Construct an English language version of the above and play it to the caller.
Still, like I said, question-answering systems have been able to do something like this in toy domains for decades, so why can't the HMRC get it right?
If you listened to transcripts of what people actually say when they call the tax authorities you would wonder how trained people ever get it right: the confusions, mis-steps, misunderstandings; the clarificatory questions needed to get an intelligible query out of the caller, the open-endedness of the topics which prompted the call ... .
After knowledge engineers spent thousands of hours trying to hand-craft ever-increasing databases of semantic nets (or their equivalents) capturing all the everyday world issues underlying lay-people's queries, it eventually became clear that the task never ends and that it's all way too expensive.
---
In case you think that the idiot-savant 'new AI' of neural net 'deep learning' is going to:
- solve the world's problems
- steer the Google car
- answer all our tax queries
I refer you to the current MIT Technology Review, where we see the superficial strengths and deep structural weaknesses of contemporary learning and statistical methods as applied to human speech ("How an AI Algorithm Learned to Write Political Speeches").
"Valentin Kassarnig at the University of Massachusetts, Amherst, .. has created an artificial intelligence machine that has learned how to write political speeches that are remarkably similar to real speeches.Here's a sample (as boring and content-free as you would expect).
"The approach is straightforward in principle. Kassarnig used a database of almost 4,000 political speech segments from 53 U.S. Congressional floor debates to train a machine-learning algorithm to produce speeches of its own.
"These speeches consist of over 50,000 sentences each containing 23 words on average. Kassarnig also categorized the speeches by political party, whether Democrat or Republican, and by whether it was in favor or against a given topic.
"Of course, the devil is in the details of how to analyze this database. Having tried a number of techniques, Kassarnig settled on an approach based on n-grams, sequences of “n” words or phrases. He first analyzed the text using a parts-of-speech approach that tags each word or phrase with its grammatical role (whether a noun, verb, adjective, and so on).
"He then looked at 6-grams and the probability of a word or phrase appearing given the five that appear before it. “That allows us to determine very quickly all words which can occur after the previous five ones and how likely each of them is,” he says.
"The process of generating speeches automatically follows from this. Kassarnig begins by telling the algorithm what type of speech it is supposed to write—whether for Democrats or Republicans. The algorithm then explore the 6-gram database for that category to find the entire set of 5-grams that have been used to start one of these speeches.
"The algorithm then chooses one of these 5-grams at random to start its speech. It then chooses the next word from all those that can follow this 5-gram. “Then the system starts to predict word after word until it predicts the end of the speech,” he says."
“Mr. Speaker, for years, honest but unfortunate consumers have had the ability to plead their case to come under bankruptcy protection and have their reasonable and valid debts discharged. The way the system is supposed to work, the bankruptcy court evaluates various factors including income, assets and debt to determine what debts can be paid and how consumers can get back on their feet. Stand up for growth and opportunity. Pass this legislation.”Only good for filibusters, I would think.
Please don't anyone tell the HMRC.
No comments:
Post a Comment
Comments are moderated. Keep it polite and no gratuitous links to your business website - we're not a billboard here.